进程和线程区别也是常问的问题,这也记一下。
进程和线程
进程
可执行的程序加载到内存中,系统为它分配资源后运行中的程序称之为进程。进程是程序关于某数据集合的一次运行活动,是操作系统进行资源分配(地址空间、内存、数据栈)和调度的基本单位。
线程
线程被包含在进程中,是进程中的实际运作单位,是操作系统进行调度的最小单位。线程是属于进程的,同一进程下的线程共享相同的运行环境。
区别
-
进程是资源分配的单位;线程是CPU调度的单位。
-
进程间切换代价大;线程间切换代价小。
-
进程拥有资源多;线程拥有资源少。
-
进程间不能直接共享信息;线程间可以通过共享数据通信。
-
一个进程死掉不影响其他进程;进程下的线程死掉会导致进程死掉。
(所以写多进程的时候总是同样的错报四次hhh)
多线程
GIL
Python代码执行由Python虚拟机控制,而对Python虚拟机的访问由全局解释器锁GIL控制,它保证即使在多核心处理器上同一时刻也只有一个线程在运行。多线程环境下虚拟机的运行方式是(获得锁-切换到一个线程运行-间隔检查/sleep-睡眠-解锁)的循环。
线程在处理I/O调用的时候会释放GIL,而CPU密集型的线程会在自己的时间片内一直占用处理器。所以CPU密集型的任务不推荐使用多线程。
threading
threading的Thread类提供两种方式创建线程:1、传递一个可调用对象;2、派生一个子类,重写run方法。
import threading
from time import sleep,ctime
def loop(x):
t = ctime()
sleep(x)
print("{0} start at {1},stop at {2}".format(
threading.current_thread().getName(),t,ctime()))
return x
class MyThread(threading.Thread):
def __init__(self, target=None ,args=()):
self.result = None
return super().__init__(target=target,args=args)
#使用子类继承的好处就是更加灵活
def getResult(self):
return self.result
def run(self):
self.result = self._target(*self._args)
if __name__ == '__main__':
#使用Thread类
for i in range(4):
mythread = threading.Thread(target = loop,args = (i,))
mythread.start()
sleep(4)
#使用MyThread类
thread_list = []
for i in range(4):
my_thread = MyThread(target=loop,args=(i,))
my_thread.start()
thread_list.append(my_thread)
for t in thread_list:
t.join()
for t in thread_list:
print(t.getResult())
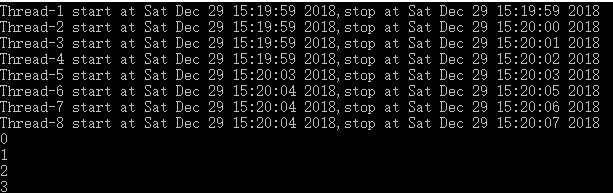
- print函数不是线程安全的,可以用sys.stdout.write方法替换。
- 这段没有线程通信,参考里有讲的很详细的文章。
多进程
Python多进程使用的是multiprocessing包,在接口定义上与threading大致相同。
import multiprocessing as mp
import sys
from time import sleep,ctime
def loop(x):
t = ctime()
sleep(x)
sys.stdout.write("{0} start at {1},stop at {2}\n".format(
mp.process.current_process(),t,ctime()))
return x
if __name__ == '__main__':
#类似于threading的用法
for i in range(4):
my_process = mp.Process(target = loop,args = (i,))
my_process.start()
sleep(4)
#使用进程池,可以获取函数的返回值
pool = mp.Pool()
res = pool.map(loop,range(4)) #map接收可迭代对象
print(res)
#阻塞执行的apply
res_list = [pool.apply(loop,(i,)) for i in range(4)]
print(res_list)
#异步非阻塞的apply_async
res_list = [pool.apply_async(loop,(i,)).get() for i in range(4)]
print(res_list)
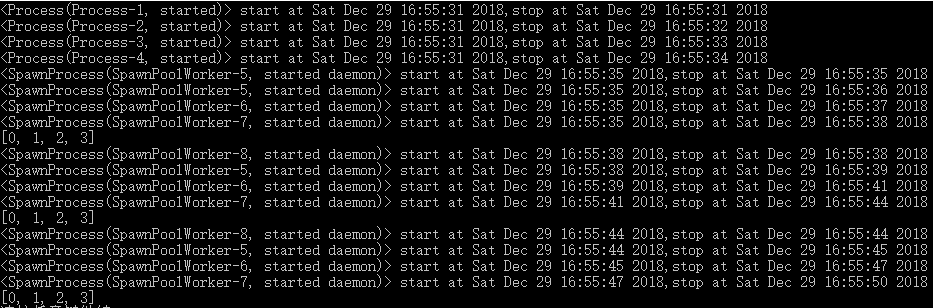
多进程有一个坑点,进程间pickle进行数据序列化传递数据,然而有些数据不能被序列化,图片来自[5]。

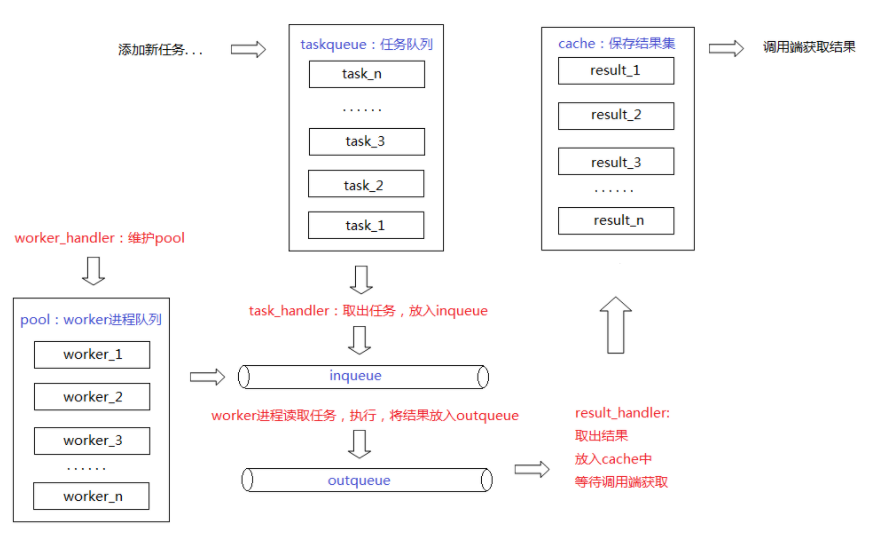
再引一张进程池工作方式的图,感觉很有用,来自[4]。
参考
[1] 了解GIL看这里http://cenalulu.github.io/python/gil-in-python/
[2] 多线程这篇内容更全面http://codingpy.com/article/python-201-a-tutorial-on-threads/
[3] 多进程pickle问题解决看这里https://strcpy.me/index.php/archives/318/
[4] 进程池源码解析http://www.codexiu.cn/python/blog/939/
[5] https://docs.python.org/2/library/pickle.html#what-can-be-pickled-and-unpickled
PPS终于重新开始记笔记了。